캐시와 서버 상태
캐시와 서버 상태 개념을 react-query에 대입하여 설명하는 글입니다.
업로드 날짜: 2024년 7월 28일❗️
해당 글은 CS의 캐시를 react-query에 대입하여 설명하는 글입니다. 이는 100% 글쓴이의 개인적인 생각이므로 비판적으로 글을 바라볼 필요성이 있습니다.
⁉️ 캐시에 대해서 아시나요?
컴공과, 혹은 관련 학과 출신이라면 필수적으로 듣는 운영체제나 컴퓨터 구조와 같은 과목에서 캐시에 대한 내용을 종종 접할 수 있습니다.
출처-위키 백과
폰 노이만 구조를 띄고 있는 컴퓨터에서는 메모리에 있는 데이터 및 명령어들을 cpu로 버스를 통해 가져와 실행하게 됩니다.
이때 물리적으로 메모리가 cpu보다 느릴 수밖에 없는데요. 이로 인해서 반응성이 떨어지는 문제가 존재합니다.
이를 해결하기 위해서 물리적으로 더 가깝게 메모리보다 빠른 캐시를 중간에 두게 됩니다.
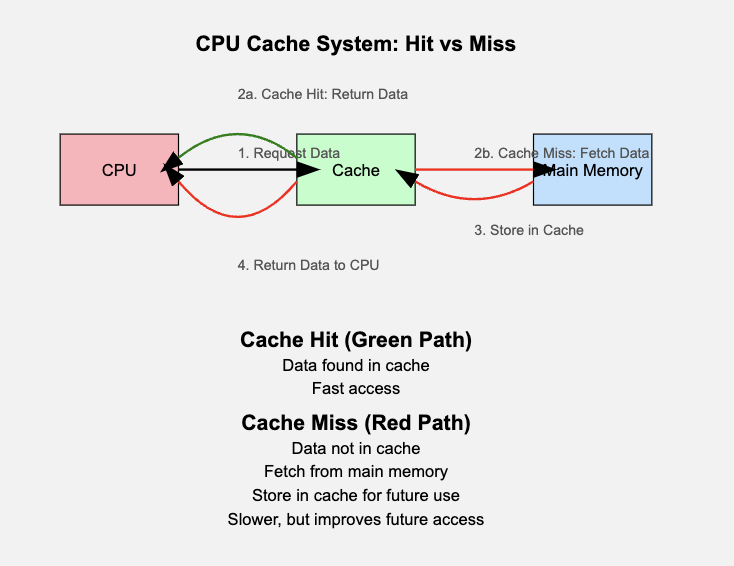
캐시에는 사용된, 혹은 사용될 데이터를 저장해두는데요. 덕분에 만약 찾고자 하는 데이터가 이미 cache에 있다면 더욱 빠르게 가져올 수 있습니다! 또한 데이터의 로컬리티적 특성 덕분에 대체로 어떤 데이터가 사용될지에 대해서도 어느 정도 예상이 가능하기도 합니다.
예를 들면 이런 것들입니다.
- “한번 사용한 데이터는 다시 재사용 될 확률이 높다.”
- “사용된 부분의 그다음 데이터를 사용할 가능성이 높다. “
- (명령문을 가져와 실행했다면, 그 다음 실행될 명령문은 다음 줄(다음 주소)일 것이다.)
이처럼 생각보다 캐시의 개념은 정말 간단합니다!
캐시 개념 확대하기_웹(web)
사실 이렇게 깊이 있게 캐시에 대해서 알지 못해도, 대부분의 사람들은 캐시라는 말을 많이 들어보셨을 것 같습니다. 캐시라는 용어를 cpu-memory의 폰 노이만 구조 외에도 다양한 곳에서 사용하기 때문인데요. 저희도 해당 개념을 좀 넓혀 웹에 대입해 보겠습니다.
- 데이터를 가지고 있는 메모리를 웹 서비스에서 전체적인 데이터를 다루는 서버로,
- 데이터를 소비하는 cpu를 웹 서비스에서 데이터를 통해 ui를 보여주는 브라우저(혹은 클라이언트)로 볼 수 있을 것 같습니다!
- 그리고 이동 수단인 버스를 네트워크로 볼 수 있겠네요!
생각보다 서버와 클라이언트 간의 통신은 불안정하고, 느립니다. 사용자 입장에서 좋은 경험을 주어야 하는 웹 개발자 입장에서는 이러한 비용을 줄이는 것이 큰 과제인데요. 🤔 여기에도 동일하게 캐시를 적용해 볼 수 있지 않을까요?
서버 데이터를 관리하는 react-query

React와 함께 자주 사용되는 라이브러리로 react-query가 존재합니다. 이는 서버 데이터 상태를 관리하는 라이브러리인데요.
먼저 서버 상태가 무엇인지를 정의해야 할 것 같습니다.
우선 리액트에서는 상태(state)를 기반으로 코드를 작성합니다. 이는 하나의 데이터로, 상태값이 변하게 되면 해당 부분을 최신화된 상태값으로 다시 렌더링을 해주게 됩니다.
상태값은 크게 두가지로 나눠볼 수 있을 것 같습니다.
- 클라이언트 상태 : 사용자 인터페이스의 일시적 상태를 관리
- ex) 모달 창의 열림/닫힘 상태, 폼 입력값 등
- 서버 상태 : 외부 서버에서 가져온 데이터 관리.
- ex) 사용자 프로필 데이터, 게시물 리스트 등
즉 서버 상태란 서버에서 가져온 데이터로, 해당 데이터의 변경에 따라 재렌더링을 해줘야 합니다.
간단히 fetch 문을 통해서 가져온 데이터를 상태에 저장해 줄 수 있을 것 같습니다.
function TodoList() { const [todos, setTodos] = useState([]); const [isLoading, setIsLoading] = useState(false); const [error, setError] = useState(null); useEffect(() => { const fetchTodos = async () => { setIsLoading(true); try { // 데이터를 fetching 합니다. const response = await fetch('https://api.example.com/todos'); const data = await response.json(); // 이렇게 가져온 데이터를 상태값에 넣어줍니다. setTodos(data); } catch (err) { setError(err); } finally { setIsLoading(false); } }; fetchTodos(); }, []); if (isLoading) return <div>Loading...</div>; if (error) return <div>Error: {error.message}</div>; return ( <ul> {todos.map(todo => ( <li key={todo.id}>{todo.title}</li> ))} </ul> ); }
물론 데이터값만 다루면 안 됩니다. (isLoading, error와 같은) 데이터가 어떤 상태인지 또한 상태값으로 관리해줘야 합니다. 그래야 유저에게 현재 상태에 올바른 ui를 보여줄 수 있을 겁니다.
음.. 코드를 보니 서버 요청 로직과, 이를 상태로 저장하는 로직이 컴포넌트에 있으니까 생각보다 조금 복잡하네요.. 그래도 아직은 봐줄 만한 정도 인 것 같습니다. 그러니 조금 더 들어가 봅시다.
이전에 설명한 캐싱 기억하시나요? 위와 같이 fetch를 하고 상태를 저장하는 시간을 단축하기 위해, 이전에 한번 요청을 했던 데이터는 캐시에 저장하도록 하면 조금 더 좋을 것 같습니다.
캐싱까지 구현을 해보기 위해 WeekMap을 만들어 이를 클로저로 두어 사라지지 않게 하고, 서버 요청 로직을 책임을 분리하고 캐싱 로직을 재사용하기 위해서 데코레이터 패턴으로 만들 수 있을 것 같습니다만.. 생각만 해도 너무나 복잡한 것 같습니다🤯🤷♂️.. 데이터 하나를 가져오려고 코드 작성에 너무나도 많은 비용이 들어가는 것을 알 수 있습니다.
이러한 문제점을 해결해 줄 수 있는 라이브러리가 존재합니다. 그게 바로 react-query입니다.
❗️
react-query는 단순히 서버 요청 관련 보일러 플레이트를 줄이기 위해 나온 라이브러리가 아닙니다. 서버 요청 및 서버 상태와 관련한 여러 문제상황에 대한 솔루션을 제공하고 있습니다. 과거에 Redux와 같은 전역 상태 라이브러리가 가진 여러 책임들 중에서 서버 상태를 나누어 관리하기 위해서 나왔다고 생각하는 것이 조금 더 맞는 방향입니다!
❗️주의❗️ 또한 react-query는 위에서 설명한 대로 WeekMap 및 클로저와 데코레이터로 만들어졌다는 말이 아닙니다. 구현 사항이 궁금하다면 깃허브 코드를 참고하셔도 좋을 것 같습니다.
react-query 의 동작 방식
react-query의 동작은 위에서 설명한 캐시에 대입해서 생각해 보면 정말 간단합니다. 서버 요청에서 중간 다리인 캐시의 역할을 해주고 있기 때문이지요!
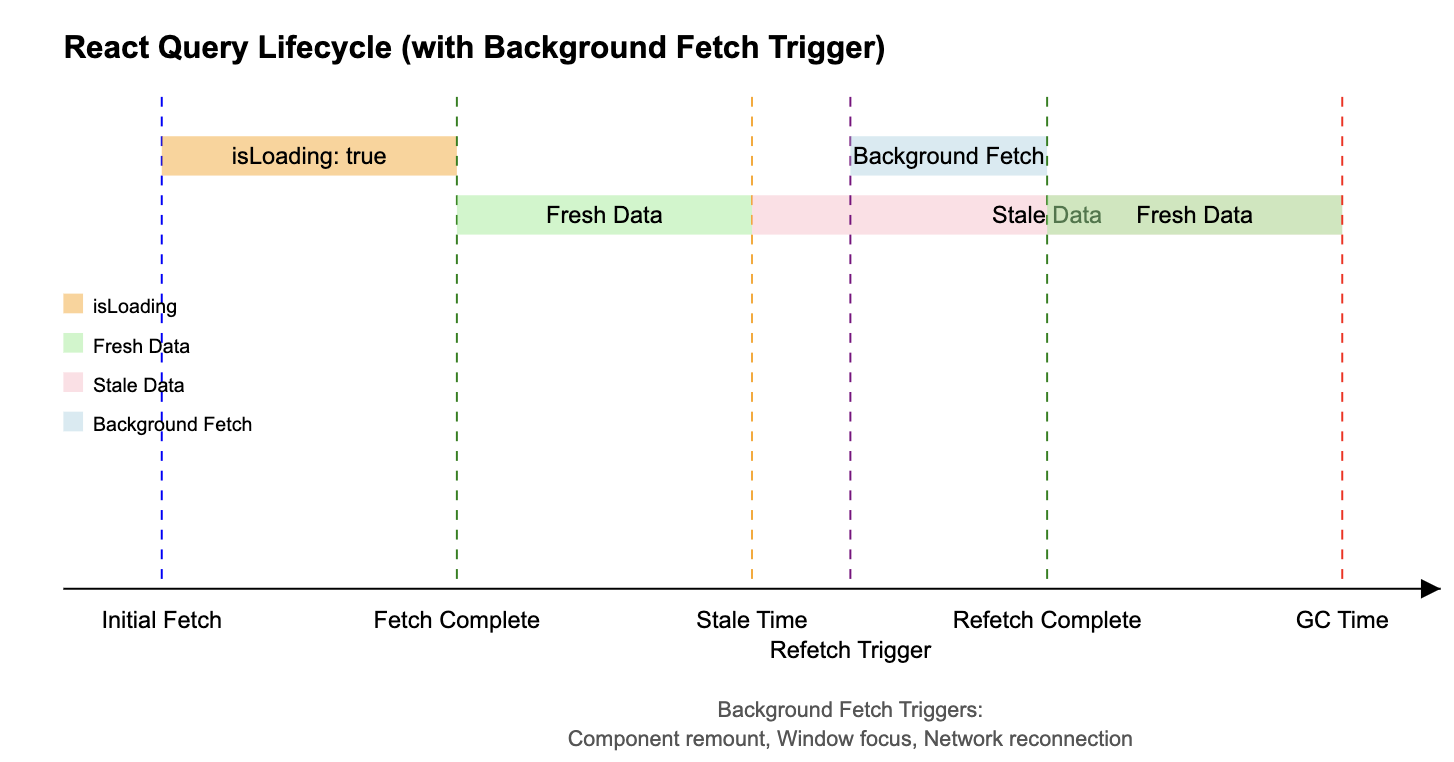
- 우선 서버의 데이터들을 캐싱 해 둡니다.
- 만약 캐싱 된 값이 없다면 fetch를 진행합니다.
- 받아온 값으로 지정된 key에 캐싱 해 둡니다.
- 만약 캐싱 된 값이 있다면 해당 데이터를 가져옵니다.
- 데이터의 상태가 fresh 하다면 아무런 조치를 취하지 않습니다.
- 데이터의 상태가 stale하다면 백그라운드에서 서버로 fetch 하며, 받아온 데이터로 새롭게 캐시를 변경합니다.
- 만약 캐싱 된 값이 없다면 fetch를 진행합니다.
여기서 들 수 있는 의문은 언제까지 fresh time 인지 일 겁니다. 이는 useQuery를 사용할 때 변경이 가능합니다.
react-query를 사용함으로써 개발자는 엄청난 성능적 이득을 볼 수 있습니다. 다만, 적절하게 stale time과 같은 값을 조절하는 것이 개발자의 역량이라고 볼 수도 있겠네요!
다만.. 좋다고 아무렇게나 사용하면 안됩니다_캐싱 전략
다시한번 컴퓨터 구조의 캐시를 가져오겠습니다.
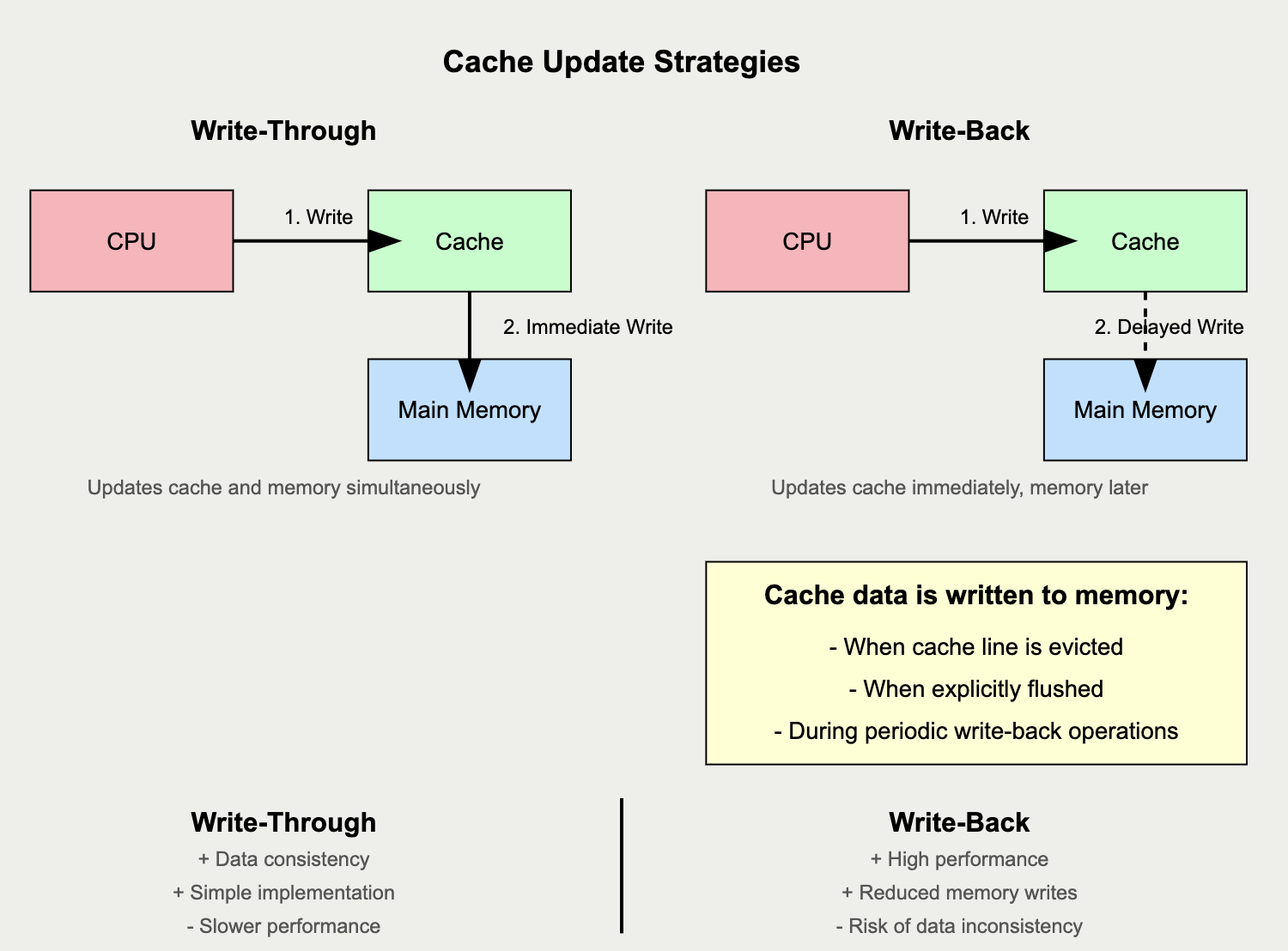
캐시에 들어있는 데이터 일부를 가져와 cpu는 일을 수행할 것입니다. 이때 데이터를 변경 후 저장해야 하는 경우가 존재하는데, 이때 캐시와 메모리의 동기화 전략에는 몇 가지가 존재합니다.
- Write-Through
- 캐시의 값이 변경되었을 때 매번 메모리에도 해당 데이터를 변경해 준다.
- 이는 캐시와 메모리에 있는 동일한 데이터가 동일한 값을 가진다.
- 매번 메모리에 접근하게 되므로 성능적으로 좋지 않다.
- Write-Back
- 데이터값이 변경되면, 캐시에만 값을 변경하며, 메모리는 변경하지 않는다.
- 이후에 만약 해당 데이터가 캐시에서 내려가게 되면 그때 메모리에 반영한다.
- Write-Through 방식의 성능적인 문제점을 개선하기 위하여 나오게 되었다.
이러한 캐시-메모리 동기화 전략을 캐시의 개념이 적용된 react query에서도 볼 수 있는데요!
서버와 동기화하기
웹에서 서버 데이터값을 변경해야 하는 상황이 있다고 생각해 보겠습니다. 서버의 상태가 변경됨에 따라서 캐시에 저장된 값과 실제 서버에 저장된 데이터가 다를 수 있습니다. 유저의 입장에서는 분명히 데이터가 바뀌어야 하는데, 캐싱 된 이전의 데이터만 보여주게 되면 많이 당황스러울 것 같습니다. 캐싱 된 데이터를 새로운 데이터로 변경할 필요가 있습니다. 새롭게 가져와서 해당 데이터로 다시 저장하면 해결할 수 있을 것 같습니다.
react-query에서 이에 대한 솔루션을 제공하고 있는데요. 바로 invalidateQuery 입니다. 참고 링크
await queryClient.invalidateQueries(
{
queryKey: ['posts'],
exact,
refetchType: 'active',
},
{ throwOnError, cancelRefetch },
)
이를 실사용에서는 mutated에서 성공했을 때 실행할 함수를 넣는 필드인 onSuccess에 넣어줌으로써 사용할 수 있습니다.
실제로도 이런식으로 많이 짤 수 있는데요. 제가 24년도 1학기에 참여한 eeos에도 이러한 로직이 들어있습니다.
export const useCreateTeam = () => {
const queryClient = useQueryClient();
const queryKey = ["teams", "all"] as const;
return useMutation({
mutationKey: queryKey,
mutationFn: (teamName: string) => createTeam(teamName),
onMutate: () => {
queryClient.invalidateQueries(["teams", "all"]); // mutate 상태일 때 캐시를 삭제해버린다.
}
});
};
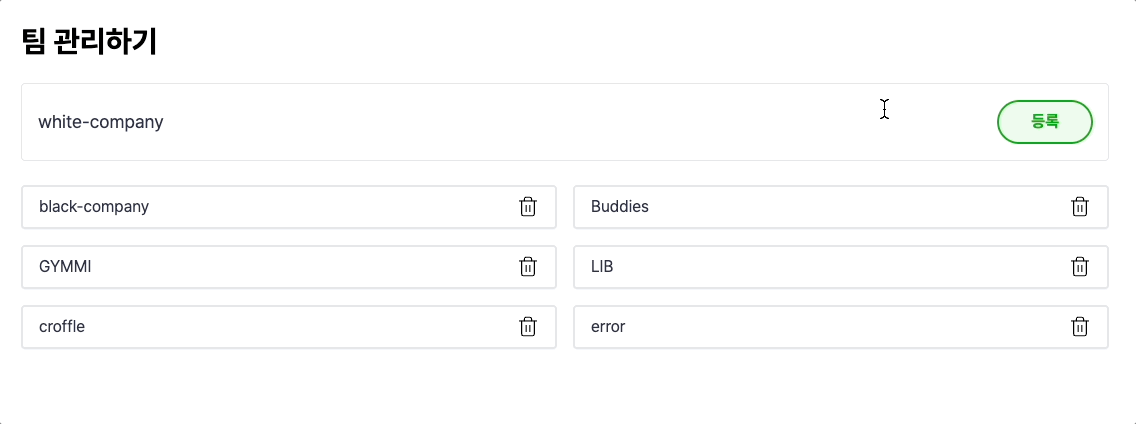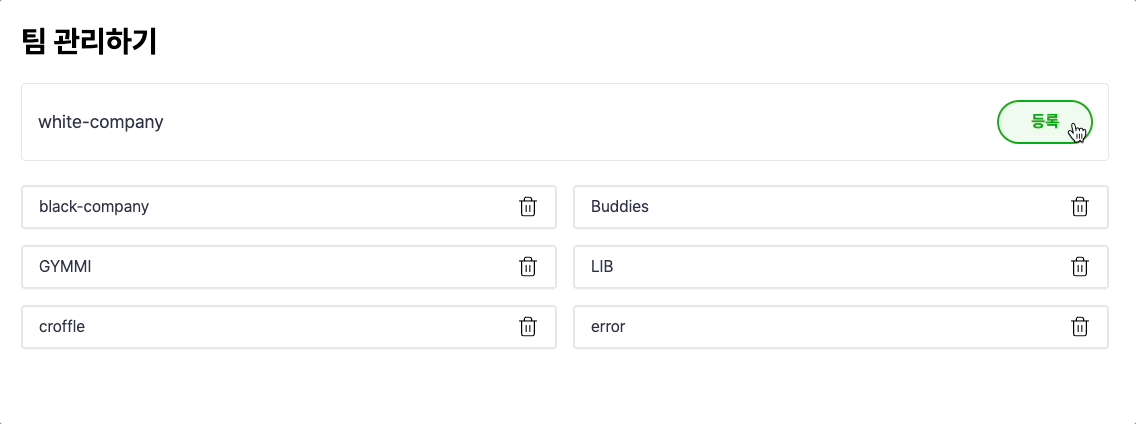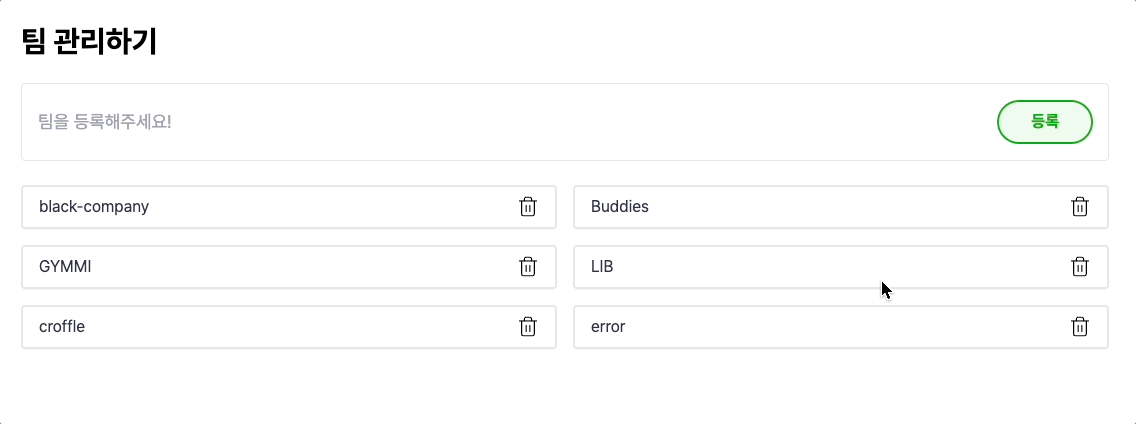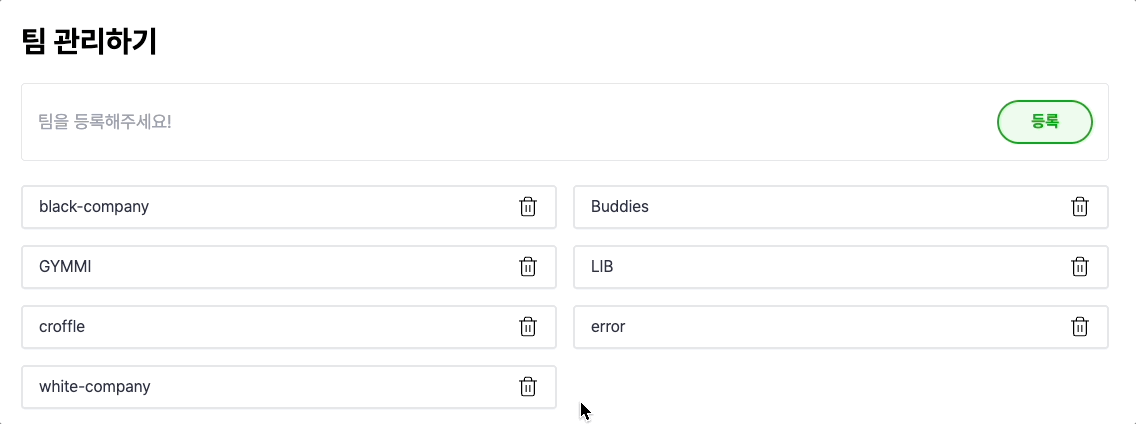
음 좋네요! 잘 동작합니다. 값을 변경할 때마다 서버와 동기화되어서 해당 값을 다시 가져와서 사용하므로 신뢰도가 있는 코드입니다. 마치 캐시의 write-through와 유사합니다.
EEOS 에 대해서 궁금하신가요? ∙ EEOS 링크 : https://econo.eeos.store/ ∙ EEOS dev 발표 : https://www.youtube.com/live/L0XSyKOznSY?si=rw1PpwGlCCXOdNPO&t=5626
하지만, 해당 코드가 만능은 아니었는데요.. 재 요청을 해야 한다는 점에서, 만약 데이터가 자주 변경되어야 한다면 어느 정도 성능적으로 문제가 발생할 수 있습니다. 위의 영상에서도 그리 빠른 느낌이 들지 않습니다. 유저의 입장에서는 당연히 좋은 경험을 할 수는 없겠네요..
조금 더 빠르게 결과물을 받아볼 수는 없을까요..?
낙관적 업데이트
react-query가 저장하고 있는 데이터가 상태값 이라는 점에 주목을 할 필요가 있습니다. 즉 이는 개발자가 어느정도 조작이 가능하다는 말과도 동일하다고 볼 수 있을 것 같습니다.
실제로 react-query에서는 상태 값을 가져오는 것 뿐만 아니라 상태 값을 변경할 수 있는 솔루션이 있습니다. 만약 서버의 데이터가 어떤 값으로 변경될지 예상이 가능하다면, 실제 서버의 데이터를 기다리지 않고 바로 상태 값을 업데이트해서 ui로 보여줄 수 있지 않을까요?
실제로 이와 관련한 내용이 공식문서에 있는데요..!
const queryClient = new QueryClient()
// Define the "addTodo" mutation
queryClient.setMutationDefaults(['addTodo'], {
mutationFn: addTodo,
onMutate: async (variables) => {
// Cancel current queries for the todos list
await queryClient.cancelQueries({ queryKey: ['todos'] })
// Create optimistic todo
const optimisticTodo = { id: uuid(), title: variables.title }
// Add optimistic todo to todos list
queryClient.setQueryData(['todos'], (old) => [...old, optimisticTodo])
// Return context with the optimistic todo
return { optimisticTodo }
},
onSuccess: (result, variables, context) => {
// Replace optimistic todo in the todos list with the result
queryClient.setQueryData(['todos'], (old) =>
old.map((todo) =>
todo.id === context.optimisticTodo.id ? result : todo,
),
)
},
onError: (error, variables, context) => {
// Remove optimistic todo from the todos list
queryClient.setQueryData(['todos'], (old) =>
old.filter((todo) => todo.id !== context.optimisticTodo.id),
)
},
retry: 3,
})
// Start mutation in some component:
const mutation = useMutation({ mutationKey: ['addTodo'] })
mutation.mutate({ title: 'title' })
// If the mutation has been paused because the device is for example offline,
// Then the paused mutation can be dehydrated when the application quits:
const state = dehydrate(queryClient)
// The mutation can then be hydrated again when the application is started:
hydrate(queryClient, state)
// Resume the paused mutations:
queryClient.resumePausedMutations()
주요 부분을 하나씩 풀어보면 아래와 같습니다.
await queryClient.cancelQueries({ queryKey: ['todos'] }): 해당 쿼리 키에 대한 진행 중인 쿼리를 취소한다. 이는 데이터를 일관성을 유지하기 위함이다.- 위의 로직에서 데이터를 수정함과 동시에 다른 곳에서 fetch를 하거나 변경하는 등의 작업이 겹쳐 데이터의 일관성이 훼손될 수 있기 때문이다.
- 한마디로 경쟁 상태를 막기 위한 방법이다.
queryClient.setQueryData(): 해당 쿼리 키의 상태값을 입력한 값으로 변경한다.onMutate : () => {return { optimisticTodo }}: onMutate에서 리턴한 값은 다른 상태값에서 사용이 가능한 context값이 된다.- 이는 실패시에 정확히 해당 변경된 값만 가져와 빼기 위함으로 보인다.
직접 상태값에 접근해서 해당 값을 변경해보도록 하겠습니다. 변경된 eeos 코드를 봐봅시다.
export const useCreateTeam = () => {
const queryClient = useQueryClient();
const queryKey = ["teams", "all"] as const;
return useMutation({
mutationKey: queryKey,
mutationFn: createTeam,
onMutate: async (teamName: string) => {
await queryClient.cancelQueries(queryKey); // 진행중인 쿼리 작업 중지
// 이전 데이터 가져오기
const previousTeams = queryClient.getQueryData<{ teams: TeamInfo[] }>(
queryKey,
);
// 만약 캐싱이 되어있다면 새롭게 변경될 데이터로 상태값 업데이트
if (previousTeams) {
const newTeam: TeamInfo = { teamId: Date.now(), teamName };
queryClient.setQueryData(queryKey, {
teams: [...previousTeams.teams, newTeam],
});
}
// 이전 데이터 컨텍스트에 담기
return { previousTeams };
},
onError: (err, newTeam, context) => {
// 에러가 발생했고, 이전 데이터가 있었다면 이전 데이터로 돌리기
if (context?.previousTeams) {
queryClient.setQueryData(queryKey, context.previousTeams);
}
},
onSettled: () => {
// 뮤테이션이 성공하든 실패하든 최신 데이터를 가져오도록
queryClient.invalidateQueries(queryKey);
},
});
};
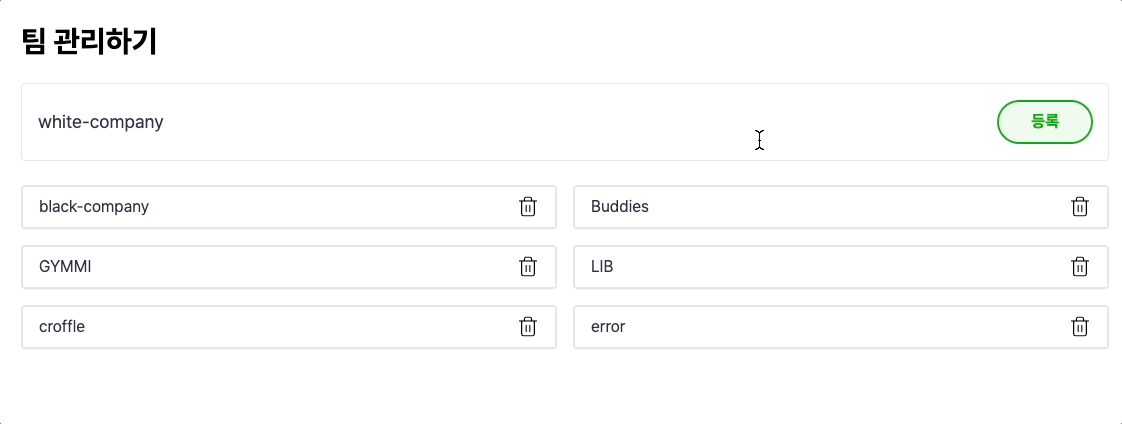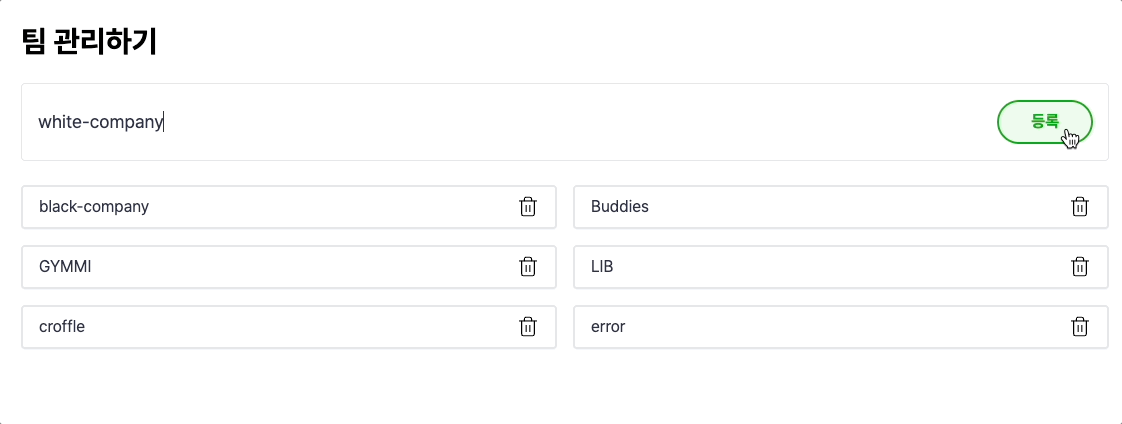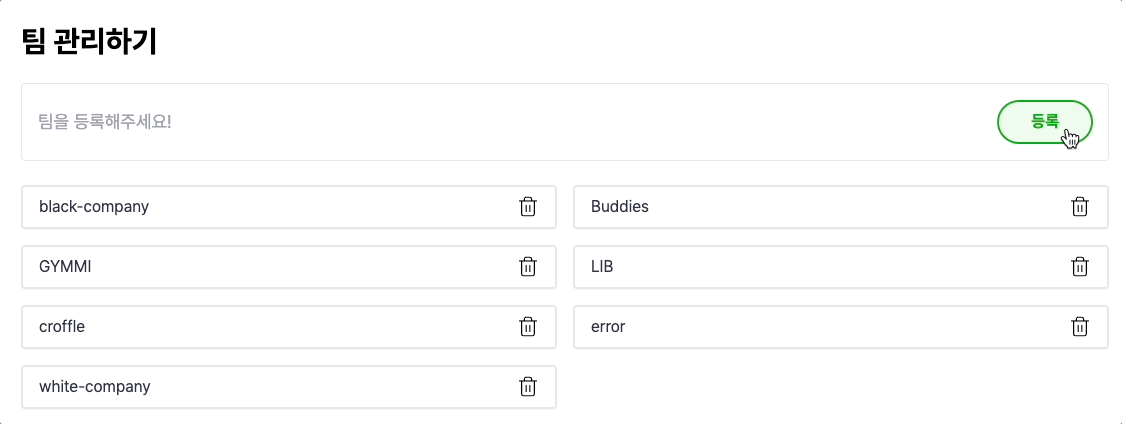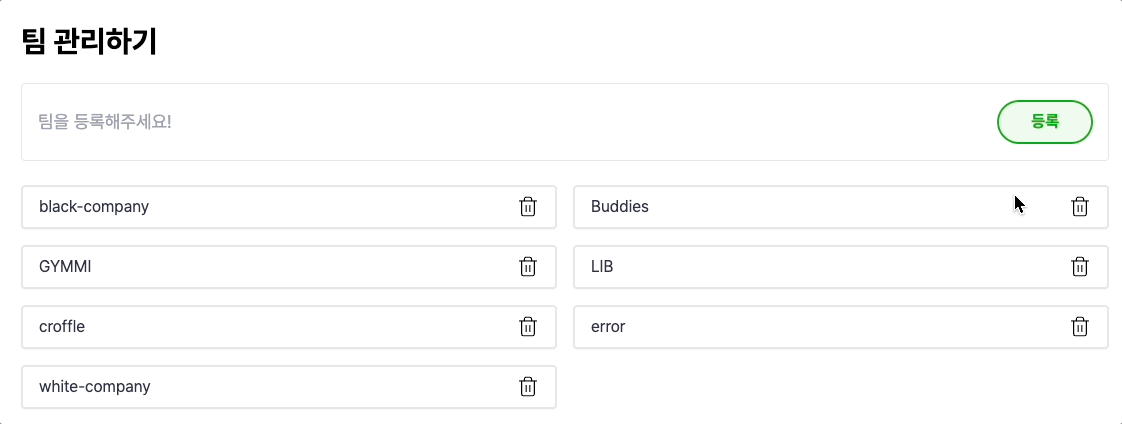
와우.. 확실히 빨라진 것을 볼 수 있네요..!
낙관적 업데이트 방식은 Write-Through의 느린 성능을 개선한 Write-Back 과 유사한 느낌이 드네요!
결론
지금까지 컴퓨터 구조에서의 캐시 개념을 웹 개발로 확장해 보며 이 역할을 해주는 react-query에 대해서 알아보았습니다.
react-query는 서버 상태관리의 핵심 도구로, 현재로서는 리액트를 사용한다면 거희 필수적으로 사용되는 라이브러리가 되었습니다.
다만 이를 어느정도 잘 사용해아만 합니다. 유저의 관점에서 어떻게 성능을 최적화 할 수 있을지에 대해서 고민해볼 필요가 있습니다.
아래는 조금 더 개념적으로 공부할만한 페이지들 입니다.
- react-query 기술 블로그 : https://tanstack.com/query/latest/docs/framework/react/community/tkdodos-blog#5-testing-react-query
- tanstack-query : https://tanstack.com/